Oct 25, 2020
I’ve been testing and improving scaling on Bitcoin Cash since 2016, as we have been focusing on other topics for a while there has not been a whole lot visible progress, and with this post I want to rectify that.
Moving Baseline
Back in 2016 I worked on the Bitcoin Classic client and we did a test in cooperation with Roger Ver to see how fast this client was able to validate all blocks till that date.
We actually stored the video online on youtube.
The result was that it took nearly 7 hours for, back then, 75GB of Blockchain. A total validation rate of 368 million transactions per day.
Last year a new test was done on the same software, but with many scaling-fixes, and it only took 2 hours on a Xeon server and a similar test on a 1st gen threadripper (32 cores) took 2h54. It is relevant to notice that by this time the Blockchain had doubled in size. Leading us to conclude that the actual speedup is between 4 and 6 times since the initial version we started with.
We basically benefit from both faster hardware and better software.
To reach some goal for scaling we thus need to always look at two factors. On one side we gain scaling capacity simply by the hardware improving. Even with zero change in software or architecture we eventually will be able to on-board those 5 billion people.
The second factor is the software architecture improving: on the same hardware we will get much better numbers with better approaches and improved algorithms.
These two factors are in near-perfect alignment: increase both by a factor 2 and your system scales by a factor 4. Etc.
Scaling Goals
In 2009 Satoshi Nakamoto famously said that Bitcoin could scale by increasing its block size. We never really hit a scaling ceiling.
This sounds really optimistic until you start to run the numbers. In my personal optimization work I’ve seen the beginning of this curve and there is a lot of data to show this is not a fluke. The simple point is that exponential growth is extremely powerful.
Underlying the growth we can achieve is the steady growth we have seen for 50 years in computer hardware. This growth is popularly known as Moore’s law and it is exponential.
Exponential growth is where the number of transactions we can process doubles every period, or in Flowee it went 700% in 3 years. Add a multiplier every couple of years and before long you are talking really serious numbers.
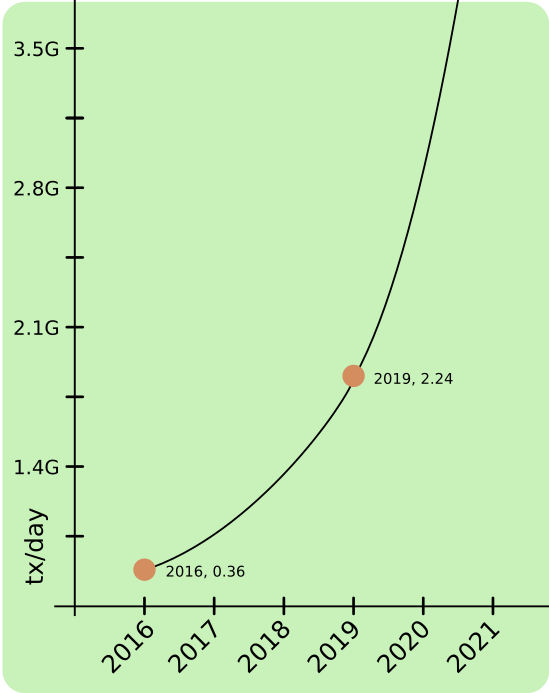
Lets assume as a scaling goal the entire world, which is about 5 billion (no need to count children) and lets say each has an average of 3 transactions a day. Leading us to 15B tx/day.
In 2016 we had 0.36G, in 2019 it was 2.24. It takes just 5 more such steps in order to reach the goal of 15 billion transactions a day.
Architectural Changes for Scaling
As the founder of Flowee a very significant part of my time has been working on scaling in the full node BCH client “Flowee the Hub”.
In this time my experience shows a couple of things that are relevant to scaling and may not be immediately obvious to people:
- To actually benefit from hardware improvements we need to go multi-threaded.
- The main bottle-neck for scaling is the UTXO as all threads need to access that.
- Actual signature validation is cheap (assuming transactions stay <= 1MB).
- 1 million transactions in one block are much cheaper to process than the same amount of transactions in many blocks.
- Block-transfer times don’t really show up on the list of problems for scaling.
- The flexibility we have with things like header-first mining means that block-transfer times become a problem much much later than everything else.
- Validation really big blocks creates a problem with memory-access.
Memory-locality becomes important to avoid the CPU waiting for data. Because of this you want to keep more important things in memory than block-data you are not yet processing.
Flowee the Hub scaling status
In the full node Flowee the Hub quite some progress has been made on the way to scaling to really large transaction counts. Most of these changes are unique to this full node, giving it a long term advantage in the space.
Block loading and memory
Blocks are no longer parsed several times and no longer stored fully in memory during validation.
Counting mem-allocs showed that the block-parsing allocated 4 times the actual block-size in memory during load. Keeping 3x memory allocated as long as the block was in memory. This memory then can’t be used for actually useful things like the UTXO.
In Flowee the Hub we stopped doing these absurd number of memory-allocations and just smoothly map into memory the data as we need it which additionally means that block-size no longer is constrained by the size of internal memory.
The approach we chose was heavily influenced by the requirement to allow smooth access to the data from many cores, the reasoning being that if we don’t have to do memory-allocations in the application, then we completely avoid race-conditions and locking.
A new UTXO database has been designed
The UTXO lookup and delete steps of transaction and block validation is the only part that has a definite need to be serialized in some way. Two threads need to be certain they are not spending the same Unconfirmed Transaction Output. So some locking is needed.
This has the effect that the UTXO is the only component that can’t be massively multi-threaded. But there is a lot of improvement that can be had over the previous design which was completely single-threaded.
In Flowee a new UTXO database has been designed which is mostly lock-free and thus enables multi-threaded access for both insert and delete.
On modest hardware we get some 25000 transaction/second processing speed.
Transaction validation is fully multi-core.
After the previous two milestones were reached the much coveted multi-core processing of transactions came into reach. The main requirement is to avoid rewriting the validation code, so a multi-threaded framework was created and the code from Bitcoin Core was moved into it.
The end result is a system that processes transactions on all threads, which includes the UTXO access. The next block can be checked for all consensus rules while we are still appending the current one.
This also allows Flowee the Hub to make the still single-threaded processing of network-messages less heavy by moving processing of new transactions to a different thread, avoiding the wait that older clients had.
Block file storage moved to 1GB
The block-files are saved on disk in pools of 1GB, allowing larger blocks to be stored.
Flowee the Hub has been tested with 250MB blocks
In 2019 a local testnet was created and a chain of blocks was created where the largest block reached 250MB. The chain reached 3GB which was validated multiple times which reached an average speed of approx 7 seconds for a 50MB block (21500 tx/sec).
Scalenet
In October 2020 a new testing network, with its own genesis block, was introduced in a cooperation between various full nodes. This Scalenet is meant to have big blocks (between 50MB and 250MB) which provides nodes a way to do plug-fest type testing.
This allows multiple full nodes to focus on scaling in a constructive and slightly competitive way.
Further projects
-
Modern database technologies will be useful to further get more speed out of the UTXO, this is relevant as it is a major bottle-neck during block-processing.
-
Optimizations take time and resources to do properly, this is an ongoing process.
-
Mining architecture has evolved through many steps into a rather wasteful design that we should take the time to re-think from first principles. [more]
-
XThinner and other block-propagation protocols to remove 99.5% of the data that needs to be send as a new block is found.
-
Adaptive blockSize. A way to protect the network from blocks that are too large while never again needing to manually increase the block-size-limit.
-
UTreeXO commitment. A way to safely allow a full node to get started on the network by just downloading the block-headers and the UTXO database.
Flowee has as its goal to move the world to a Bitcoin Cash economy. Do you agree that we are well on our way to reach this scale?